

Data Fabric 和 Data Mesh 是新兴的数据管理概念,旨在解决组织变革以及在混合多云生态系统中理解、管理和使用企业数据的复杂性。这两个数据架构概念是互补的。但究竟什么是数据编织和数据网格,如何使用这些数据管理解决方案来利用企业数据来做出更好的决策?
一 什么是数据编织
Gartner 将数据编织定义为“一种设计概念,用作数据和连接过程的集成层。数据编制利用对现有的、可发现的和推断的元数据的持续分析来支持跨所有环境(包括混合和多云平台)的集成和可重用数据集的设计、部署和利用。”
数据编织架构方法可以简化组织中的数据访问,并促进大规模的自助数据消费。这种方法打破了数据孤岛,为塑造数据治理、数据集成、单一事实视图和可信赖的人工智能实施以及其他常见行业用例提供了新的机会。换句话说,数据访问、数据集成和数据保护的障碍被最小化,为最终用户提供最大的灵活性。
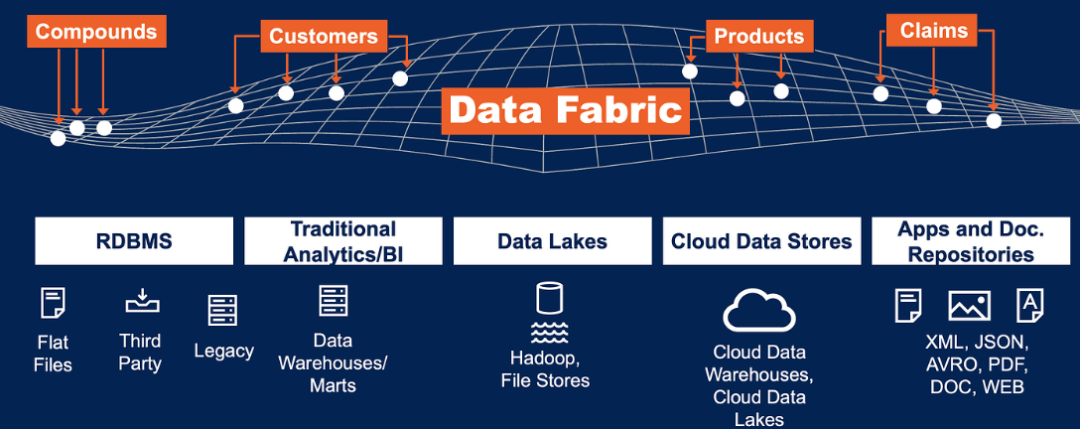
使用这种方法,组织不必将所有数据移动到一个位置或数据存储,也不必采用完全分散的方法。相反,数据编织架构意味着需要在逻辑上或物理上分散的内容与需要集中的内容之间取得平衡。由于这种平衡,可以参与数据编织生态系统的专用数据存储的数量没有限制。这意味着将获得一个全局数据目录,该目录用作抽象层、单一事实来源和具有注入治理的单点数据访问。
二 数据编织的六个核心功能
1.知识目录:此抽象层为360度客户视图提供对数据的通用业务理解,从而实现透明度和协作。知识目录充当一个图书馆,其中包含有关数据的见解。为了帮助了解数据,该目录包含业务词汇表、分类法、数据资产(数据产品)以及相关信息,例如质量得分、与每个数据元素关联的业务术语、数据所有者、活动信息、相关资产等。
2.自动数据丰富:要创建知识目录,需要自动数据管理服务。这些服务包括自动发现和分类数据、检测敏感信息、分析数据质量、将业务术语链接到技术元数据以及将数据发布到知识目录的能力。为了处理企业内部如此庞大的数据量,自动化数据丰富需要由机器学习驱动的智能服务。
3.自助服务管理数据访问:这些服务使用户能够轻松地查找、理解、操作和使用具有关键管理功能的数据,例如数据分析、数据预览、向数据集添加标签和注释、在项目中协作以及使用 SQL 接口在任何地方访问数据或 API。
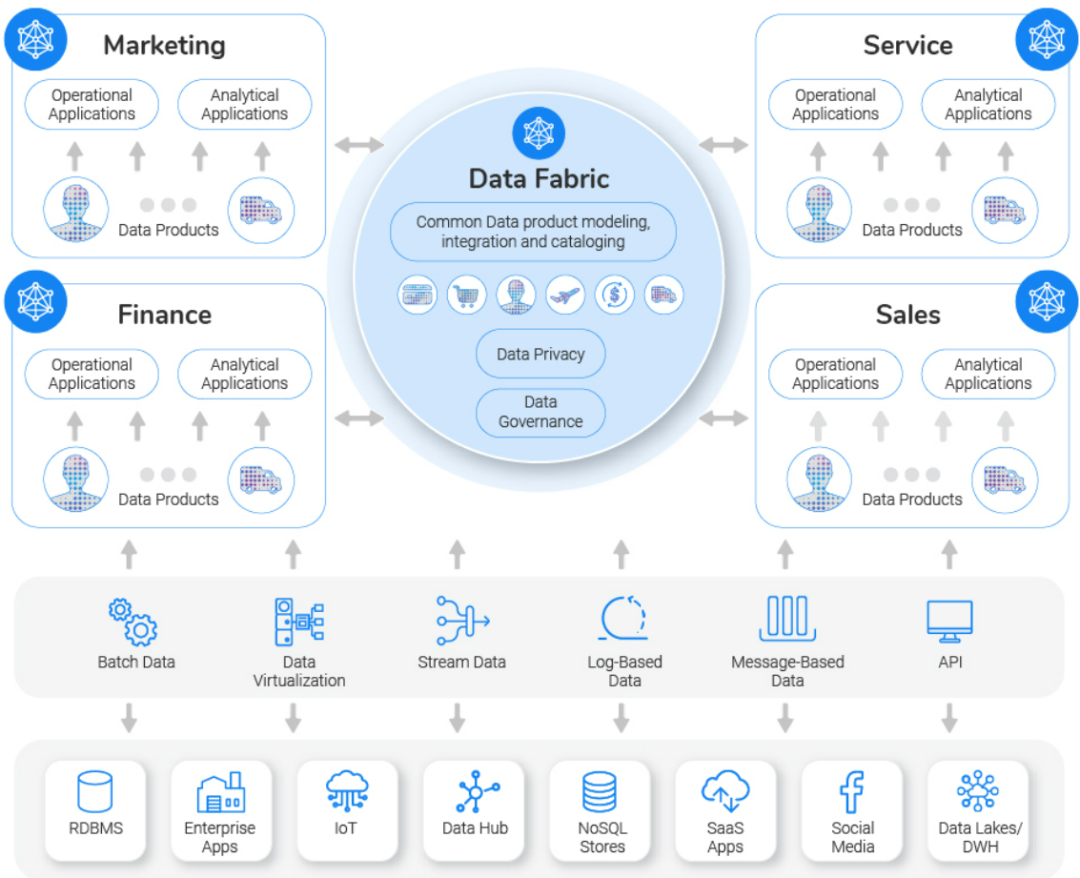
4.智能集成:数据集成功能对于提取、摄取、流式传输、虚拟化和转换数据至关重要,无论数据位于何处。使用旨在同时最大化性能和最小化存储和访问成本的数据策略,智能集成有助于确保数据隐私。保护应用于每个数据管道。
5.数据治理、安全性和合规性:使用数据编制,可以通过统一且集中的方式来创建策略和规则。通过元数据(例如数据分类、业务术语、用户组、角色等)自动将这些策略和规则链接到各种数据资产的能力很容易获得。这些政策和规则,包括数据访问控制、数据隐私、数据保护和数据质量,然后可以在数据访问或数据移动期间在所有数据中大规模应用和强制执行。
6.统一生命周期:端到端生命周期,使用 MLOps 和 AI 在统一体验中组合、构建、测试、部署、编排、审查和管理数据编制的各个方面,例如数据管道。
Data Fabric 架构的这六项关键功能使数据消费者能够更加信任和自信地使用数据。无论数据是什么,或驻留在何处——无论是在传统数据中心还是混合云环境中,在传统数据库或 Hadoop、对象存储或其他地方——Data Fabric 架构都为数据访问和使用提供了一种简单且集成的方法,为用户提供自助服务并使企业能够使用数据来最大化其价值链。
三 什么是数据网格
根据 Forrester 的说法,“数据网格是一种分散的社会技术方法,用于在复杂和大规模的环境中共享、访问和管理分析数据——在组织内部或跨组织使用。”
Data Mesh的主要目标是超越利用数据仓库和数据湖的传统集中式数据管理方法。Data Mesh 通过赋予数据生产者和数据消费者访问和管理数据的能力来强调组织敏捷性的理念,而无需将任务委托给数据湖或数据仓库团队。Data Mesh 的分散方法将数据所有权分配给特定领域的组,这些组将数据作为产品提供服务、拥有和管理。
Data Mesh 的实施提高了希望在不确定的经济环境中蓬勃发展的组织的组织敏捷性。所有组织都需要能够以低成本、高回报的方式应对环境变化。引入新的数据源、需要遵守不断变化的监管要求或满足新的分析要求都是促使组织数据管理活动发生变化的驱动因素。当前的数据管理方法通常基于操作和分析系统之间复杂且高度集成的 ETL,这些系统努力及时改变以在面对这些驱动因素时及时支持业务需求。Data Mesh 的目的是针对数据提供一种更具弹性的方法,以有效地响应这些变化。
四 数据网格的四个基本原则
是由Zhamak Dehghani在2019 年创造的,基于四个基本原则:
领域所有权原则要求领域团队对其数据负责。根据这一原则,分析数据应该围绕域组成,类似于与系统的有界上下文对齐的团队边界。遵循领域驱动的分布式架构,分析和操作数据所有权从中央数据团队转移到领域团队。
数据作为产品原则将产品思维哲学投射到分析数据上。这个原则意味着域外的数据有消费者。领域团队负责通过提供高质量的数据来满足其他领域的需求。基本上,域数据应该被视为任何其他公共 API。
自助数据基础设施平台背后的想法是将平台思维应用于数据基础设施。一个专门的数据平台团队提供与领域无关的功能、工具和系统来为所有领域构建、执行和维护可互操作的数据产品。借助其平台,数据平台团队使领域团队能够无缝地使用和创建数据产品。
联邦治理原则通过标准化实现所有数据产品的互操作性,由治理组通过整个数据网格来推动。联邦治理的主要目标是创建一个遵守组织规则和行业规则的数据生态系统。
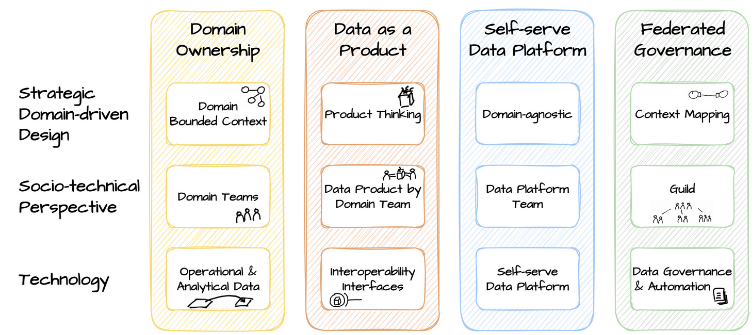
数据网格架构是一种将业务领域或功能的数据源与数据所有者对齐的方法。通过数据所有权去中心化,数据所有者可以为他们各自的领域创建数据产品,这意味着数据消费者,包括数据科学家和业务用户,可以使用这些数据产品的组合来进行数据分析和数据科学。
数据网格方法的价值在于,与依赖数据工程师清理和集成下游数据产品相比,它将数据产品的创建转移给最了解业务领域的上游主题专家。
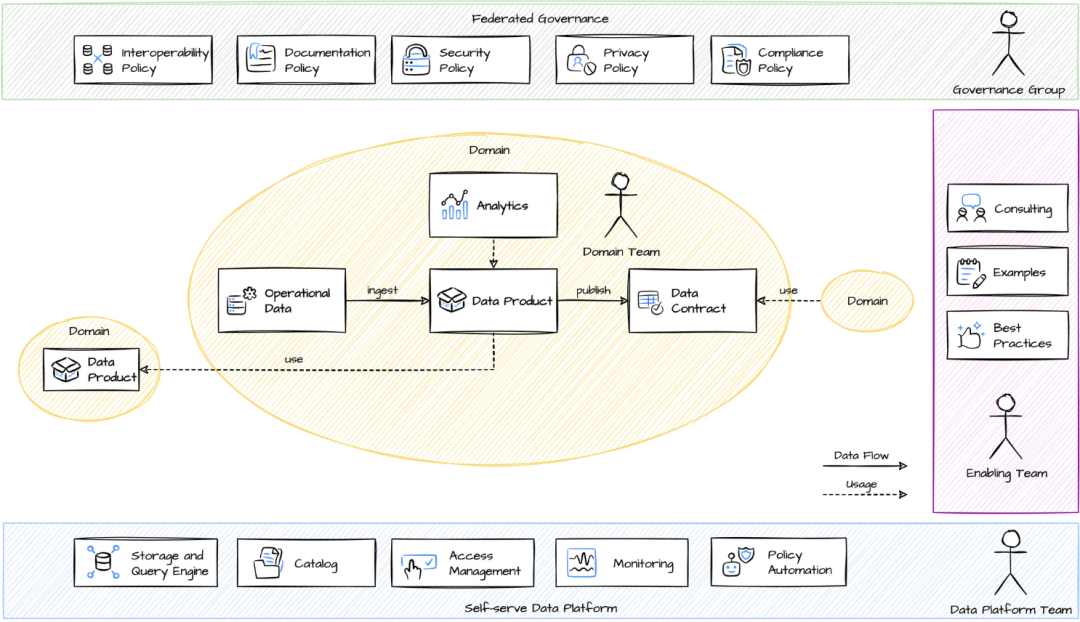
此外,数据网格通过启用发布-订阅模型和利用 API 加速数据产品的重用,这使数据消费者更容易获得他们需要的数据产品,包括可靠的更新。
五 数据编织与数据网格的关系
数据编织和数据网格可以共存。事实上,数据编织可以通过三种方式实现数据网格:
1.为数据所有者提供数据产品创建功能,例如对数据资产进行编目、将资产转化为产品以及遵循联合治理策略
2.使数据所有者和数据消费者能够以各种方式使用数据产品,例如将数据产品发布到目录、搜索和查找数据产品以及利用数据虚拟化或使用 API 查询或可视化数据产品。
3.通过学习模式作为数据产品创建过程的一部分或作为监控数据产品过程的一部分,使用来自数据编织元数据的见解来自动化任务
在数据管理方面,数据编织通过自动执行创建数据产品和管理数据产品生命周期所需的许多任务,提供了实施和充分利用数据网格所需的功能。通过使用数据编织基础的灵活性,您可以实施数据网格,继续利用以用例为中心的数据架构,无论数据驻留在本地还是云端。





